Desde el primer día que monté mi actual PC y le instalé Debian he tenido demoras
en el arranque del sistema. En concreto, el proceso se quedaba clavado durante
unos segundos cuando (supuestamente) estaba configurando la red, mientras la
pantalla de arranque mostraba:
[ ok ] Mounting local filesystems... done.
[ ok ] Activating swapfile swap... done.
[ ok ] Cleaning up temporary files....
[ ok ] Setting kernel variables ... done.
[....] Configuring network interfaces...
Si utilizaba DHCP (la IP dinámica era otorgada por el router), ese tiempo de
espera aparecía intermitentemente en algunos de los arranques junto con un
extraño mensaje de asignación de IP del cliente DHCP. Si empleaba en cambio una
IP estática, asignada manualmente por mí, el retraso aparecía siempre.
Durante mucho tiempo he creido que el origen del problema era el propio driver
de la tarjeta de red Intel e1000e, ya que en los logs del kernel aparecían un
par de líneas extrañas, "IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready" y
más tarde "IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready" que me
tuvieron despistado. Esta familia de tarjetas había tenido algún bug serio, así
que los bug tracking systems estaban llenos de referencias a logs con estos
mensajes, lo que complicaba la búsqueda. Al final encontré en el README del
driver de Intel, casi al final de la sección de "Known Issues", el siguiente
fragmento:
> Link may take longer than expected
> ----------------------------------
>
>
> With some Phy and switch combinations, link can take longer than expected.
> This can be an issue on Linux distributions that timeout when checking for
> link prior to acquiring a DHCP address; however there is usually a way to work
> around this (for example, set LINKDELAY in the interface configuration on
> RHEL).
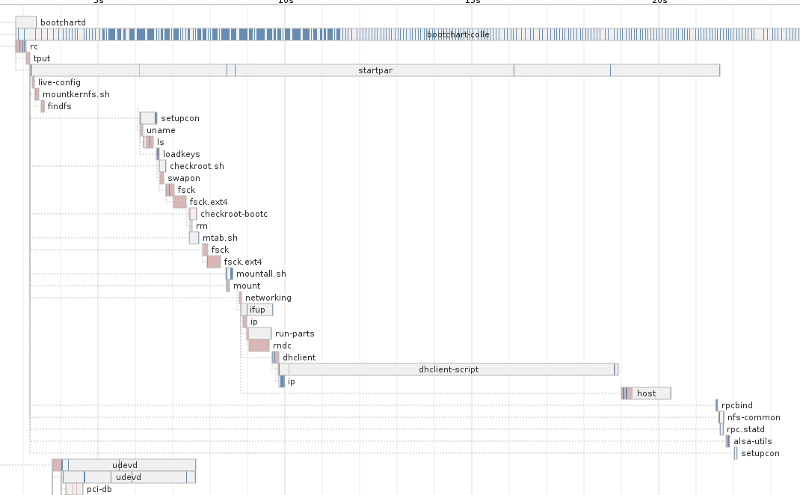
También estuve usando durante un mes bootchart2 para obtener
gráficas de tiempos del proceso de arranque. Los arranques sin problemas de
retraso rondaban los 15-16 segundos, mientras que los que tenían retraso
variaban desde los 20 a los 27 segundos, alcanzando en un caso excepcional ¡los
59 segundos! De todo este montón de información lo que me llamó la atención era
un proceso llamado dhclient-script, que aparecía "alargado" durante segundos
en los arranques con retraso, como por ejemplo en éste:
Tanto el comentario del README como los resultados de bootchart2 me llevaron a
pensar que era un problema exclusivamente de la tarjeta de red, y por lo tanto
que sólo la propia gente de Intel podía resolver en el código del driver.
Actualizaba el kernel cada vez que cambiaban algo en el driver, esperando a que
alguna vez "sonara la flauta". Y probablemente algo así ha pasado, porque si
miro el último kernel compilado, los mensajes sobre el link not ready/ready
siguen apareciendo en el kernel, sólo que actualmente el tiempo que transcurre
entre ambos mensajes es de aproximadamente 1,5 segundos:
[ 10.034797] e1000e 0000:00:19.0: irq 41 for MSI/MSI-X
[ 10.138513] e1000e 0000:00:19.0: irq 41 for MSI/MSI-X
[ 10.138633] IPv6: ADDRCONF(NETDEV_UP): eth0: link is not ready
[ 11.658786] e1000e: eth0 NIC Link is Up 100 Mbps Full Duplex, Flow Control: Rx/Tx
[ 11.658790] e1000e 0000:00:19.0 eth0: 10/100 speed: disabling TSO
[ 11.658821] IPv6: ADDRCONF(NETDEV_CHANGE): eth0: link becomes ready
Pero el problema del retraso persistía, aunque la situación había mejorado lo
suficiente como para poder usar una IP estática con un tiempo de arranque
asumible.
Más adelante, en otra tanda de investigaciones, encontré que desactivando los
scripts que se llaman en un ifup no había retrasos, lo que me llevó a
descubrir que la demora se producía concretamente dentro del script
/usr/lib/avahi/avahi-daemon-check-dns.sh. Es más, a base de hacer debugging
del script fuí capaz de acotar el lugar donde se producía exactamente:
OUT=`LC_ALL=C host -t soa local. 2>&1`
if [ $? -eq 0 ] ; then
if echo "$OUT" | egrep -vq 'has no|not found'; then
return 0
fi
else
# Checking the dns servers failed. Assuming no .local unicast dns, but
# remove the nameserver cache so we recheck the next time we re triggered
rm -f ${NS_CACHE}
fi
return 1
El culpable era el comando host -t soa local. Y además averigüé, mostrando la
hora antes y despues, que el retraso era siempre de 10 segundos. Tenía toda la
pinta de que el comando host estaba esperando una respuesta hasta que sus
timeouts se agotaban. Sin embargo, el problema parecía limitarse al arranque,
ya que invocando host -t soa local en la línea de comandos el tiempo de espera
era inapreciable.
Ahora que conocía el problema, no me fue difícil encontrar que ya existía un bug
abierto con el problema en el BTS de Debian: Bug #559927 (lo cual
era un alivio, porque significaba que no era el único pringao con el bug).
Había una solución sencilla para evitar el retraso, que era eliminar el comando
en cuestión. Pero todavía no sabía qué hacía ese comando y el script en
general, así que ignoraba cuáles eran las repercusiones que ello podía acarrear.
No ha sido hasta hace unos días que me he puesto otra vez con este bug y he
conseguido resolverlo defintivamente.
Avahi
Avahi es una implementación libre de la especificación
Zeroconf de Apple, y si quieres saber qué significa eso mejor que
mires los enlaces a Wikipedia que he puesto. El caso es que Avahi se usa para
descubrir recursos en la red local como impresoras y unidades de red, entre
otras cosas, por lo que CUPS (el subsistema de impresión de Linux que también
lo es de Mac OS X) lo emplea. Yo, como la mayoría del mundo, tengo una impresora
local conectada por un puerto USB, así que todo esto del descubrimiento de
impresoras en la red en realidad me sobra. Sin embargo los que definen las
dependencias en Debian no piensan lo mismo y Avahi es una dependencia
Recommends: de CUPS. Si tienes una impresora y por lo tanto CUPS, es casi
seguro que tienes instalado Avahi.
Pero hay un problema: Avahi se basa en multicast DNS (mDNS), una forma de DNS
en el que se interroga a través de IPs multicast a toda la red local, buscando
otros equipos con Avahi/Zeroconf. Zeroconf está definido bajo una zona DNS
especial cuyo dominio es .local (por ejemplo miequipo.local o
mordor.local). Y aunque .local está reservado, hay gente que no lo sabe y
que lo usa como parte de su FQDN para su equipo o su red local, poniéndolo en su
/etc/host o lo que es peor, como una zona en su servidor DNS. Y cuando esto
sucede hay problemas, porque ahora los nombres de dominio *.local puede
resolverse tanto a través de multicast DNS como de unicast DNS.
Para evitar esta situación, en el paquete Debian escribieron un script que
comprueba precisamente esto: si existe (se puede resolver) un dominio .local
en el DNS actual. Si existe, Avahi no arrancará, y se avisa de ello al
administrador del equipo para que tome las medidas oportunas. Si no se resuelve,
Avahi puede lanzarse con la seguridad de que no habrá problemas con la
resolución de .local a través del mDNS. Para hacer esta comprobación, lo que
hace el script es literalmente llamar al DNS usando host. Huelga decir que
este script es, naturalmente, el mencionado avahi-daemon-check-dns.sh.
No contentos con esto, y debido a algún bug abierto, los mantenedores de Avahi
decidieron que era buena idea hacer la comprobación de .local cada vez que se
levantara o reiniciara un interfaz de red (por ejemplo cada vez que te conectes
a una WiFi y te asigne nuevos DNS via DHCP). Y para ello lo que hicieron es
naturalmente enganchar el script avahi-daemon-check-dns.sh a la
infraestructura de dispositivos de red de Debian, que son los scripts de
ifupdown.
¿Por qué no funciona esto? En realidad sí funciona... si no tienes un DNS local,
como es mi caso. Y es que bind9 (o el servidor de DNS que utilices) no está en
marcha hasta mucho más tarde en el proceso de arranque. Por eso el host -t soa
local funciona perfectamente desde la línea de comandos, pero falla
miserablemente cuando es invocado desde avahi-daemon-check-dns.sh cuando
ifup levanta un interfaz en el arranque del sistema. O también en ifdown en
el shutdown del mismo, cuando el servidor de DNS ya está muerto. Y es que no
lo he dicho, pero el retraso también existía en el apagado (aunque normalmente
es de esas cosas en las que no te sueles fijar mucho o darle importancia).
Aplicando el siguiente parche a /usr/lib/avahi/avahi-daemon-check-dns.sh se
puede ver el tiempo que transcurre en la llamada a host:
57a58,59
> DEBUG_HOST_CMD_TIME=`LC_ALL=C date +%T`
> echo "\n[$DEBUG_HOST_CMD_TIME] Before calling host -t soa local."
59a62,63
> DEBUG_HOST_CMD_TIME=`LC_ALL=C date +%T`
> echo "[$DEBUG_HOST_CMD_TIME] After calling host -t soa local."
63a68,69
> DEBUG_HOST_CMD_TIME=`LC_ALL=C date +%T`
> echo "[$DEBUG_HOST_CMD_TIME] After calling host -t soa local."
Para poder hacer logging de las líneas generadas con ese parche he tenido que
emplear la utilidad bootlogd. bootlogd se encarga de guardar
todo lo que se imprime en la consola al inicio del proceso de arranque, para
posteriormente volcarlo en un fichero de log /var/log/boot. Es la única forma
de hacerlo, ya que esta parte inicial del arranque sucede antes de que syslogd
esté en marcha, cuando ni siquiera está montado el root filesystem.
Sun Jun 22 09:27:11 2014: [....] Setting kernel variables ... [ok] done.
Sun Jun 22 09:27:14 2014: [....] Configuring network interfaces...
Sun Jun 22 09:27:14 2014: [09:27:12] Before calling host -t soa local.
Sun Jun 22 09:27:22 2014: [09:27:22] After calling host -t soa local.
Sun Jun 22 09:27:22 2014: [ok] done.
Sun Jun 22 09:27:22 2014: [....] Starting rpcbind daemon... [ok] .
Sun Jun 22 09:27:22 2014: [....] Starting NFS common utilities: statd [ok] .
...
Los 10 segundos se repiten siempre que empleo el DNS local (nameserver
127.0.0.1 en /etc/resolv.conf). Cuando empleo un DNS externo, por ejemplo de
mi ISP, el tiempo de host es de 2 segundos, aunque eso dependerá de lo que
tarde ese servidor DNS en enviar la respuesta (con un máximo de 10 segundos,
claro, que es lo más que espera host una respuesta del DNS).
Ahora que sabía exactamente qué estaba pasando, podía resolver el problema. De
hecho, el propio paquete Avahi proporciona una solución: se puede desactivar la
comprobación del dominio .local poniendo a 0 el valor de
AVAHI_DAEMON_DETECT_LOCAL en /etc/default/avahi-daemon. Sin embargo, yo he
optado por una solución más drástica, que es desinstalar directamente Avahi. Así
me evito futuros problemas y bugs con un software que no necesito ni uso, amén
de ahorrarme dos demonios innecesarios corriendo en el sistema.
Los resultados de bootchart2 son los siguientes: antes de eliminar el retraso un
arranque tardaba entre 25 y 26 segundos, mientras que después, desactivando la
resolución de .local, tarda de 15 a 16 segundos y desinstalando completamente
Avahi también de 15 a 16. Es un poco contraintuitivo que tarde lo mismo teniendo
que lanzar 2 procesos más que sin hacerlo, pero he hecho 4 arranques de cada
configuración para cerciorarme y eso es lo que he obtenido.
Para verlo gráficamente, aquí tenéis un informe completo de bootchart2 de cada
uno de los casos:
(Nota: las gráficas de bootchart2 no salen todas iguales, ya que el arranque en
paralelo es no determinista, y además me parece que la forma de medir de
bootchart2 tampoco es perfecta; lo que he hecho ha sido escoger la que me ha
parecido más representativa de cada una de las cuatro realizadas para cada
caso).
Desinstalando Avahi en Debian
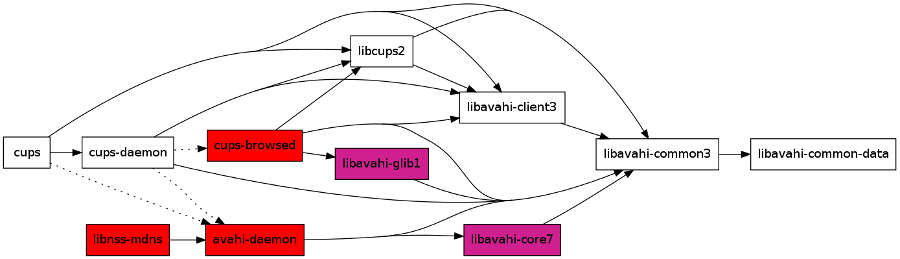
Si se observa el mapa de dependencias (limitado) de Avahi en la imagen de
arriba, se puede ver que la única manera de desinstalar Avahi sin desinstalar
CUPS es "cortar" por las recomendaciones (flechas discontínuas), es decir, por
los paquetes marcados en rojo avahi-daemon y cups-browsed (lo que también
desinstalaría por dependencias libnss-mdns). Esto permitirá desinstalar además
las bibliotecas marcadas en violeta, si es que apt no lo hace automáticamente.
Sin embargo, no es posible desinstalar todas las bibliotecas Avahi, ya que CUPS
(y puede que otros paquetes que tengas instalados) dependen directamente del
paquete de la biblioteca cliente y de la parte común. Cualquier intento de
quitar estos paquetes puede llevarse por delante muchos otros que probablemente
no quieres quitar, así que mejor dejarlo ahí.
:wq